
Knowledge of the relationship between the volume and intensity of training on the one hand and the resulting improvements in performance on the other is obviously critical when attempting to design the optimal training program, i.e., one that maximizes an individual’s performance ability at the time of key events while also avoiding illness, injury, or overtraining. To understand this relationship, most coaches and athletes rely upon some combination of tradition (i.e., knowing what has worked previously for others), empiricism (i.e., trial-and-error experimentation), and the application of basic training principles (e.g., the overload principle).
In a number of scientific studies, however, this relationship has been investigated in a more direct, quantitative manner (see Bibliography). These studies have used a wide variety of mathematical approaches, ranging from simple linear regression to complex neural networking. By far, the most common approach, however, has been to use what is typically referred to as the impulse-response model.
First proposed by Banister et al. in 1975, this model, and/or variations thereof, has been repeatedly shown to accurately predict training-induced changes in performance (both positive and negative) in a wide variety of endurance and non-endurance sports (see below). The impulse-response model has therefore been successfully used to design theoretically-ideal training programs, optimize tapering regimens, evaluate the effects (or lack thereof) of cross-training in triathletes, etc. As will be discussed, however, this model also has a number of inherent limitations, which tend to limit its usefulness outside of a laboratory setting.
The purpose of the present article is, therefore, to describe a somewhat simpler approach, termed the Performance Manager, that was developed by the present author, and in particular, to explain the etiology of this idea in the context of the impulse-response model. While some information about how to best use this analytical tool is included, readers should also see this article for more information on this aspect of the topic. The Performance Manager is available in both TrainingPeaks.com as well as TrainingPeaks WKO desktop software.
Banister’s impulse-response model: theory, applications, and limitations
In the impulse-response approach, the quantitative relationship between training and performance is modeled as a transfer function, the input to which is the daily “dose” of training (i.e., the combination of volume and intensity) and the output of which is the individual’s actual performance. The transfer function describing the behavior of the system (i.e., the athlete) is composed of two first-order filters, one representing the more long-lasting (or chronic) positive adaptations to training, which result in an increase in performance ability, and the other representing the more short term (or acute) negative effects of the last exercise bout(s), i.e., fatigue, which result in a decrease in performance ability.
The time course of changes in performance in response to repeated bouts of training is therefore described by equation 1 below:
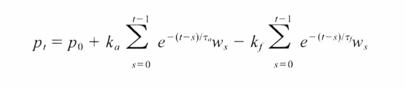
Equation 1. The impulse-response model of Banister et al.
Where pt is the performance at any time t, p0 is the initial performance, ka and kf (or k1 and k2) are gain terms relating the magnitudes of the positive adaptive and negative fatigue effects (and also serving to convert the units used to quantify training to the units used to quantify performance), τa and τf (or τ1 and τ2) are time constants describing the rate of decay of the positive adaptive and negative fatigue effects, and ws is the daily dose of training.
The model, therefore, has four adjustable parameters, i.e., ka and kf (or k1 and k2) and τa and τf (or τ1 and τ2), which are constrained such that ka<kf(or k1<k2) and τa>τf (or τ1>τ2). The best-fit solution to the model is determined iteratively, i.e., by repeatedly measuring both the daily dose of training and the resulting performance, then adjusting the values of these parameters to result in the closest correspondence between the model-predicted and actual performances.
Figure 1 below graphically illustrates the effects of a single bout of training on performance resulting in a TSS® of 100 as predicted by this model. As can be seen in this figure, performance (i.e., the difference between the two terms of the equation above) is initially predicted to be diminished or degraded due to the acute, negative influence of training. As this effect wanes, however, the positive adaptations to training begin to dominate, such that performance is eventually improved.

Figure 1. Effect of a single bout of training (TSS = 100) on fitness, fatigue, and performance as predicted by the impulse-response model. τa and τf (or τ1 and τ2) were assumed to be 42 and 7 d, respectively, whereas ka and kf (or k1 and k2) were assumed to equal 1 and 2, respectively.
The impact of repeated bouts of training on performance is then the summation of such individual impulses, with the ultimate effect (i.e., when, or even whether, training results in an increase or decrease in performance, and the extent to which this is true) depending on the magnitude and timing of each “dose” of training. This is illustrated in Figure 2, which depicts the response to a sustained increase in daily training to 100 TSS/d:
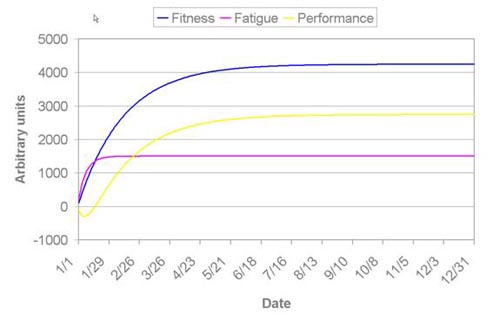
Figure 2. Changes in fitness, fatigue, and performance as predicted using the impulse-response model. The daily training load was assumed to increase on January 1 from 0 to 100 TSS/d. Model parameters as in Fig. 1
As indicated previously, the above-described model has been successfully applied to a number of different sports, e.g., weight lifting, hammer throwing, running, swimming, cycling, and triathlon, and has been shown to account for >70%, and often >90%, of the day-to-day variation in performance (i.e., the R2 between the predictions of the model and the actual data is typically >0.7 and often >0.9). Moreover, the model has also been shown to accurately predict changes in performance-related parameters considered indicative of training (over)load and/or adaptation, such as serum hormone (e.g., testosterone) or enzyme (e.g., creatine kinase) levels or psychological measures of anxiety or perceived fatigue.
The impulse-response model has therefore been used to optimize training/tapering regimens, evaluate the impact of training in one sport (e.g., running) on performance in another (e.g., cycling), etc. In most of these studies, the metric used to track training load has been Banister’s heart rate-based “training impulse” (TRIMP) score, but other ways of quantifying training have also been used (especially in studies of non-endurance sports, but also, e.g., for swimming), and, roughly speaking, the model appears to work equally well regardless of precisely how training has been quantified.
Given the rather robust behavior described above, the impulse-response model would appear to be a highly useful tool for coaches and athletes wishing to maximize their probability of success in competition, and some prominent national team programs in cycling have attempted to exploit this approach. There are, however, a number of limitations to the impulse-response model, some of which may be only academic in nature, but others of which clearly tend to limit its usefulness in a practical sense:
- While the impulse-response model can be used to accurately describe changes in performance over time, it has not been possible to link the structure of the model to specific, training-induced physiological events relevant to fatigue and adaptation, e.g., glycogen resynthesis and mitochondrial biogenesis. In that regard, the model must be considered purely descriptive in nature, i.e., largely a “black box” into which it is not possible to see. Although this by no means invalidates the approach, being able to relate the model parameters (in particular, the time constants τa and τf (or τ1 and τ2)) to known physiological mechanisms would allow the model to be applied with greater confidence and precision.
- The impulse-response model essentially assumes that there is no upper limit or upper bound to performance, i.e., a greater amount of training always leads to a higher level of performance, at least once the fatigue due to recent training has dissipated. In reality, of course, there will always be some point at which further training will not result in a further increase in performance, i.e., a plateau will occur. This is true even if the athlete can avoid illness, injury, overtraining, or just a mental “burnout”. While Busso et al. have proposed a modification to the original model that explicitly recognizes this fact and which results in a slightly improved fit to actual data, this modification further increases the mathematical complexity and requires an even larger amount of data to be available to solve the model (see below).
- To obtain a statistically valid fit of the model parameters to the actual data, it is necessary to have multiple, direct, quantitative measurements of performance. The exact number depends in part on the particular situation in question, but from a purely statistical perspective, somewhere between 5 and 50 measurements per adjustable parameter would generally be required. Since the model has four adjustable parameters, i.e., τa and τf (or τ1 and τ2) and ka and kf (or k1 and k2), this would mean that performance would have to be directly measured between 20 and 200 times in total.
Moreover, since the model parameters themselves can change over time/with training (see more below), these measurements should all be obtained in a fairly short period of time. Indeed, Banister himself has suggested revisiting the fit of the model to the data every 60-90 d, which in turn would mean directly measuring an athlete’s maximal performance ability at least every 4th day, if not several times per day. Obviously, this is an unrealistic requirement, at least outside of the setting of a laboratory research study. - Even when an adequate number of performance measurements are available, the fit of the model to the data is not always accurate enough for the results to be helpful in projecting future performance (which is obviously necessary to be able to use the impulse-response model to plan a training program). In other words, even though an adequate R2 might be obtained with a particular combination of parameter estimates, the parameter estimates themselves may not always be sufficiently stable or certain to enable a highly reliable prediction of future performance. This seems to be particularly true in cases where the overall training load is relatively low, in which case the addition of the second, negative term to the model often does not result in a statistically significant improvement in the fit to the data, i.e., the model can be said to be overparameterized.
In other studies in the literature, the parameter estimates that provide the best mapping of training (i.e., the input function to the model) to performance (i.e., the output of the model) fall precisely on the constraints imposed when fitting the model, i.e., the model has essentially been forced to fit the data. Again, while this is not necessarily an invalid approach, it suggests that either the model structure is inadequate (even if it is the best available choice) to truly describe the data or that the data themselves are too variable or “noisy” to be readily fit by the model. - As illustrated by the data shown in Table 1, the values reported in the literature for τa (or τ1) are quite consistent across studies, at least when one considers a) the wide variety of sports that have been studied (and hence the wide variety of training programs that have been employed), and b) that the model is relatively insensitive to changes in τa (or τ1 ) (i.e., increasing or decreasing τa (or τ1) by 10% changes the output of the model by <5%). Moreover, the interindividual variation in τa (or τ1) is relatively small, as indicated by the magnitude of the standard deviation compared to the mean value in each case. On the other hand, the values obtained for τf (or τ2) do vary significantly across studies and, to a somewhat lesser extent, also within a particular study (i.e., between individuals).
However, these variations in τf (or τ2) appear to be due, in large part, to differences in the overall training load. This effect is especially evident in the study of Busso (2003), in which increasing the training load (by increasing the frequency of training from 3 to 5 d/wk while holding all other aspects constant) resulted in ~33% increase in τf (or τ2). In addition, the degree to which the training might be expected to result in significant muscle damage also appears to play a role.
For example, the value for τf (or τ2) obtained in the study of Morton et al. (1990), which involved running, is comparable to that found in the study of swimmers by Iñigo et al. (1996), despite the much smaller total training load in the former study. Indeed, the highest value for τf (or τ2) reported in the literature appears to be 22±4 d in a study of elite weight-lifters, with this extreme value presumably reflecting both the nature and magnitude of the training load of such athletes. Thus, although τf (or τ2) is more variable than τa (or τ1), this variability appears explainable. In contrast, it is harder to explain the variability obtained in different studies for the gain terms of the impulse-response model, i.e., ka and kf (or k1 and k2). In part, this is because these values serve not only to “balance” the two integrals in Eq. 1, but also to quantitatively relate the training load to performance in an absolute sense.
In other words, for the same set of data/for the same individual, the values for ka and kf (or k1 and k2) would be different if performance were, for example, defined as the power that could be maintained for 1 min versus 60 s, or if training were quantified in kilojoules of work accomplished instead of TRIMP. It is clear, however, that this is not the only explanation for the variation in ka and kf (or k1 and k2) between studies, as even their ratio varies significantly, with this variation seemingly unrelated to factors such as the overall training load.
For example, the ratio of kf to ka (or k2 to k1) in the study of Busso et al. (1997) is comparable to that found by Hellard et al. (2005), despite the large difference in type and amount of training. Moreover, as indicated by the standard deviations listed in the last three columns of Table 1, the variability in ka and kf (or k1 and k2) between individuals in a given study is as large, or even larger, than the variation across studies. Because of this variability, it is difficult, if not impossible, to rely on generic values for ka and kf (or k1 and k2) from the literature to overcome the limitations discussed under points 3 and 4 above. This is especially true given the fact that the impulse-response model is more sensitive to variations in these gain factors than it is to variation in the time constants, especially τa (or τ1).
Table 1. Representative studies from the literature have used the impulse-response model.
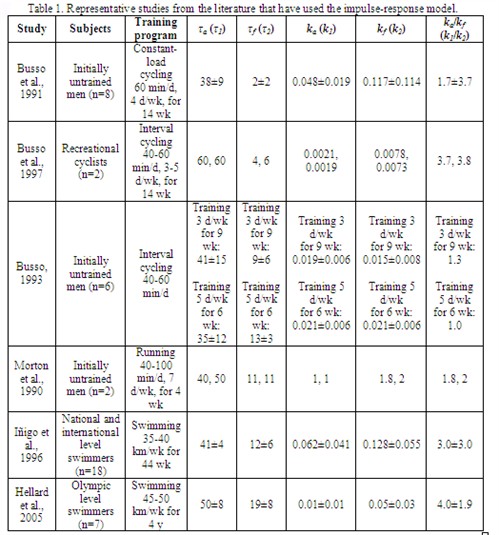
Note: The time constants τa and τf (or τ1 and τ2) are measured in days, whereas the units of the gain factors ka and kf (ork1 and k2) vary from study to study depending on how training and performance were quantified.
The Performance Manager concept: part science, part art
Given the relative complexity of the impulse-response model (at least from the perspective of most non-scientists) and the limitations discussed above, many are tempted to simply dismiss the approach out-of-hand as unbelievable “black magic,” or at the very least, as too unpractical for routine use. To do so, however, is to willfully ignore potentially valuable knowledge that has been gained via such scientific research into the quantitative relationship between training and performance.
Specifically, even though the impulse-response model may be purely descriptive in nature, studies using this approach have provided important insight into the effective time course of recovery from, and adaptation to, exercise training. Failure to apply this information when planning and evaluating training programs, tapering schemes, etc., means failure to take maximum advantage of available knowledge. Or, to put it another way: if, as Dave Harris has put it, the body responds to training “like a Swiss watch”, then logically, this information could, and should, be put to use by coaches and athletes wishing to maximize performance.
The problem, however, is how to do so in a manner that is consistent with the results of this previous scientific research yet is still simple enough to be used and applied in a real-world setting.
The above considerations led the present author to search for a practical way of applying the lessons learned via research using the impulse-response model to data obtained using a power meter. The starting point for this search was recognition of the simple fact that performance is typically greatest when training is first progressively increased to a very high level to build fitness, after which the athlete reduces their training load, i.e., tapers, to eliminate residual fatigue. Or, to put it more simply, “form equals fitness plus freshness”.
With this perspective in mind, it was recognized that eliminating the gain factors ka and kf (or k1 and k2) from the impulse-response model would solve two problems simultaneously: 1) it would remove any uncertainty regarding the precise values to use (with the price being that interpreting the results of the calculations becomes as much a matter of art as it is of science – see more below), and 2) it would allow substitution of simpler exponentially-weighted moving averages for the more complex integral terms in the original equation (because at least qualitatively they behave the same way). Based on this logic, the components of the Performance Manager were defined, i.e.,:
- Chronic training load, or CTL, provides a measure of how much an athlete has been training (taking into consideration both volume and intensity) historically or chronically. It is calculated as an exponentially-weighted moving average of daily TSS (or TRIMP, etc.) values, with the default time constant set to 42 d. CTL can therefore be viewed as analogous to the positive effect of training on performance in the impulse-response model, i.e., the first integral term in Eq. 1, with the caveat that CTL is a relative indicator of changes in performance ability due to changes in fitness, not an absolute predictor (since the gain factor, ka (or k1), has been eliminated).
- Acute training load, or ATL, provides a measure of how much an athlete has been training (again, taking into consideration both volume and intensity) recently or acutely. It is calculated as an exponentially-weighted moving average of daily TSS (or TRIMP, etc.) values, with the default time constant set to 7 d. ATL can therefore be viewed as analogous to the negative effect of training on performance in the impulse-response model, i.e., the second integral term in Eq. 1, with the caveat that ATL is a relative indicator of changes in performance ability due to fatigue, not an absolute predictor (since the gain factor, kf (or k2), has been eliminated).
- Training stress balance, or TSB, is, as the name suggests, the difference between CTL and ATL, i.e., TSB = CTL – ATL. TSB provides a measure of how much an athlete has been training recently or acutely, compared to how much they have been training historically or chronically. While it is tempting to consider TSB as analogous to the output of the impulse-response model, i.e., as a predictor of actual performance ability, the elimination of the gain factors ka and kf (or k1 and k2) means that it is really better viewed as an indicator of how fully-adapted an individual is to their recent training load, i.e., how “fresh” they are likely to be.
Thus, within the logical constructs of the Performance Manager, performance depends not only on TSB but also on CTL (in keeping with saying that “form equals fitness plus freshness”). The “art” in applying the Performance Manager, therefore, lies in determining the precise combination of TSB and CTL that results in maximum performance.
To put it another way: in the Performance Manager concept, an individual’s CTL (and the “composition” of the training resulting in that CTL – see more below) determines their performance potential (at least within limits), but their TSB influences their ability to fully express that potential. Their actual performance at any point in time will therefore depend on both their CTL and their TSB, but determining how much emphasis to accord to each is now a matter of trial-and-error/experience, not science.
To better illustrate the conceptual differences between the impulse-response model and the Performance Manager, consider Figure 3 below, which illustrates the effect on CTL, ATL, and TSB of a square-wave increase in daily training load from 0 to 100 TSS/d as of January 1st:
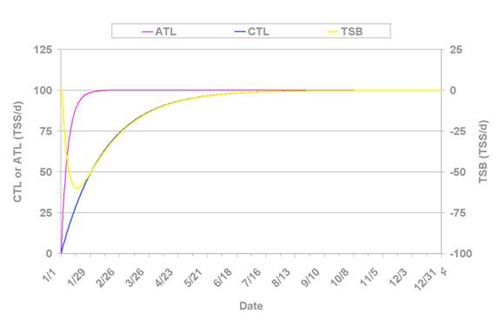
Figure 3. Changes in chronic training load (CTL), acute training load (ATL), and training stress balance (TSB) in response to a square-increase in daily training load from 0 to 100 TSS/d.
As shown in the figure, both CTL and ATL respond to this sudden increase in training in an exponential fashion, just like the fitness and fatigue components of the impulse-response model, and with identical time courses (since the time constants are the same). As well, TSB shows an initial reduction followed by an exponential rise, which is qualitatively similar to the time course of performance as predicted by the impulse-response model.
However, the minima in TSB occur later than the reduction in performance would be predicted to occur by the impulse-response model when using the same time constants (i.e., 42 and 7 d for τa and τf (or τ1 and τ2), respectively). Moreover, unlike performance as predicted using the impulse-response model, TSB never exceeds its initial level but instead rises monoexponentially to eventually equal CTL (and ATL). This differing behavior is a consequence of the elimination of the gain factors ka and kf(or k1 and k2) from the impulse-response model, as well as the substitution of exponentially-weighted moving averages for the integral sums.
After both retrospective and prospective evaluations of this approach by the author and a few others, the idea was shared with additional coaches and cyclists until, eventually, a pool of approximately two dozen “beta testers” was created (see Acknowledgements). These individuals used the Performance Manager during the 2005 and 2006 racing seasons and, in doing so, provided valuable feedback about how to best apply the approach. As part of this developmental process, a number of variations on the approach described above were tried (e.g., dynamically-varying time constants), but none proved to be discernably better than the original and simpler formulation. The decision was therefore made to incorporate the idea into version 2.1 of the program WKO+ as a new chart.
Applying the Performance Manager concept
Because successfully using the Performance Manager entails some degree of “art”, it is anticipated that users may require some time to become good “artists”. The following hints, tips, caveats, and limitations are offered in hopes of speeding up this process.
1) The concepts embodied in the Performance Manager apply regardless of how the training load is quantified. In other words, it is at least theoretically possible to use this approach to evaluate and manage one’s training when the latter is quantified using, e.g., TRIMP scores instead of TSS. At the present time, however, WKO+ only allows the use of TSS as the “input function”. Thus, to obtain good results using the Performance Manager approach, it is important that these TSS values be based upon valid, up-to-date estimates of an athlete’s functional threshold power. This is especially true since the TSS calculated for a particular workout varies as a function of the square of Intensity Factor® (IF®) (i.e., TSS = duration (h) x IF2 x 100), and hence the inverse square of the assigned functional threshold power (since IF = normalized power/functional threshold power).
In other words, decreasing the value assumed for functional threshold power by, say, 4% (e.g., using 240 W instead of 250 W) increases the TSS for a particular workout by just over 8%. In turn, this will have commensurate effects on CTL, ATL, and TSB. Indeed, it is sometimes possible to identify periods of consistent over-or underestimation of functional threshold power when an individual’s actual response to training deviates significantly from that expected based on the Performance Manager approach.
2) The Performance Manager approach is predicated on the assumption that an athlete will use their powermeter during every workout and race, such that a value for TSS is available for every workout. However, it is not at all uncommon for individuals to choose to race without their powermeter, for data files to be corrupted during collection (e.g., if the memory of the powermeter is exceeded) or lost during downloading, for the powermeter to stop working entirely, etc. In such cases, it is necessary to estimate any missing TSS, or again the output of the Performance Manager will be distorted. This is especially true of CTL, and hence also of TSB, due to the long time constant used in its calculation. Missing values for TSS can be estimated in a number of different ways:
a) from a “library” of comparable workouts that the athlete has performed previously, the file(s) from which can be copied into the Calendar of WKO+ on the appropriate date;
b) from heart rate data (if available), which can be used to estimate the normalized power that was sustained, and hence to calculate TSS manually (see formula under point #1 above). These data can then be entered directly into WKO+ by first manually creating a workout in the Calendar and then overriding the TSS value that is assigned by default.
c) by simply assuming a value for IF and then calculating TSS manually and entering into the program as described under b). When using this approach, it is useful to recall the typical IF values associated with different types of training sessions and races, i.e.,
- <0.75 level 1 recovery rides
- 0.75-0.85 level 2 endurance training sessions
- 0.85-0.95 level 3 tempo rides, various aerobic and anaerobic interval workouts (work and rest periods combined), longer (>2.5 h) road races
- 0.95-1.05 level 4 intervals (work period only), shorter (<2.5 h) road races, criteriums, circuit races, 40k TT (by definition)
- 1.05-1.15 shorter (e.g., 15 km) TT, track points race
- >1.15 level 5 intervals (work period only), prologue TT, track pursuit, track miss-and-out
Although intuitively, approach b might seem best (since it is based on actual data), in reality, there is little to recommend this more complex approach over the other two, as it is often possible for experienced powermeter users to estimate their TSS just as, if not more, accurately without ever knowing their heart rate. Moreover, any error introduced into the calculation of CTL, etc., as a result of poorly estimating the true TSS for one or two missing workouts is likely to be minimal.
On the other hand, if a large amount of data is missing (e.g., >10% of all files for a particular block of time), then the output of the Performance Manager calculations during and following that period should be interpreted with considerable caution. In turn, this emphasizes the importance of racing with a powermeter since individuals often incorporate frequent racing into their training program when attempting to peak.
3) Related to the above, the long time constant for CTL means that data must be collected for a fairly long period of time before the Performance Manager calculations can be considered accurate (cf. Fig. 3). Obviously, however, a new powermeter user will not have a large database of files that can be analyzed to determine their starting point. Similarly, a long-time powermeter user who hasn’t paid sufficient attention to tracking changes in their functional threshold power may not wish to rely on their previous data, or they may be without their powermeter for a lengthy period of time (e.g., while it is being repaired).
In such cases, it may be necessary to “seed” the model with starting values for CTL and ATL by using the “Customize this chart” option for the Performance Manager chart in WKO+. The appropriate value to use can be estimated by realizing that most people train at an intensity resulting in 50-75 TSS/h (i.e., average weekly IF is usually between ~0.70 and ~0.85). Those who train more, mostly or entirely outdoors, and/or in a less structured fashion would likely fall towards the lower end of this range, whereas those who train less, frequently indoors, and/or in a more structured fashion would tend to fall towards the upper end of this range. Unless there is a specific reason to do otherwise (e.g., transitioning from using a spreadsheet to track TSS to using the Performance Manager within WKO+), the same value should be assigned to CTL and ATL (i.e., TSB is assumed to be zero).
Over time, of course, an individual’s CTL will become evident, in which can it may prove necessary, or at least desirable, to go back and revise these initial estimates. Of course, as discussed under point #2 above the calculated values for CTL, ATL, and TSB should be interpreted cautiously following such a “seeding” until sufficient data are available.
4) As should be evident from previous discussion, the Performance Manager concept is especially useful when attempting to reach peak performance on a particular date. In practice, this entails deciding how much ATL, and hence CTL, should be reduced so as to result in an increase in TSB. Or, to put it another way, how much “fitness” should be given up or sacrificed in order to create more “freshness.”
Since each individual is different and since the answer to this question may depend in part of the particular aspect of performance that one is attempting to maximize, previous experience is often the best guide here. Thus, one valuable approach is to use the Performance Manager as a “lens” through which to view previous attempts at peaking, and then to use the knowledge gained by doing so to modify, or simply try to replicate, that experience.
Alternatively and/or in addition, the following approximate guidelines may prove useful when analyzing prior data: a TSB of less than ‑10 would usually not be accompanied by the feeling of very “fresh” legs, while a TSB of greater than +10 usually would be. A TSB of -10 to +10, then, might be considered “neutral”, i.e., the individual is unlikely to feel either particularly fatigued or particularly rested. The precise values, however, will depend not only on the individual but also on the time constants used to calculate CTL and ATL (see more below) and, therefore, should not be applied too literally.
5) Although most attention is likely to be focused on the application of the Performance Manager to managing the peaking process, other benefits to this approach clearly exist and should not be overlooked. For example, experience to date indicates that, across a wide variety of athletes and disciplines (e.g., elite amateur track cyclists, masters-age marathon MTB racers, professional road racers), the “optimal” training load seems to lie at a CTL somewhere between 100 and 150 TSS/d.
That is, individuals whose CTL is less than 100 TSS/d usually feel that they are undertraining, i.e., they recognize that they could tolerate a heavier training load if only they had more time available to train and/or if other stresses in life (e.g., job, family) were minimized. (Note that this does not necessarily mean that their performance would improve as a result, which is why the word “optimal” in the sentence above is in quotes).
On the other hand, few, if any, athletes seem to be able to sustain a long-term average of >150 TSS/d. Indeed, analysis of powermeter data from riders in the 2006 Tour de France and other hors category international stage races indicates that the hardest stages of such races typically generate a TSS of 200-300, which illustrates how heavy a long-term training load of >150 TSS/d would be (since the average daily TSS of, e.g., the Tour de France is reduced by the inclusion of rest days and shorter stages (e.g., individual time trials), and it is generally considered quite difficult to maintain such an effort for 3 wk, much less for the 3+ mo it would take for CTL to fully “catch up”).
Of course, even if this general guideline of 100-150 TSS/d eventually proves to be incorrect, this does not change the fact that the Performance Manager approach makes it possible to quantify the long-term training load of any athlete in a manner that a) takes into account, via TSS, the volume and intensity of their training relative to that individual’s actual ability (i.e., functional threshold power), and b) does so in a manner that is consistent with the effective time course of adaptation to training, as determined using the impulse-response approach.
6) In addition to the absolute magnitude of CTL, considerable insight into an individual’s training (and/or mistakes in training) can often be obtained by examining the pattern of change in CTL over time. Specifically, a long (e.g., 4-6 wk) plateau in CTL during a time when a) the focus of training has not changed, and b) the athlete’s performance is constant is generally evidence of what might be termed “training stagnation” – that is, the individual may feel that they are training well, by being very “consistent” and repeatedly performing the same workouts, but in fact they are not training at all, but simply maintaining because the overload principle is not being applied.
On the other hand, attempting to increase CTL too rapidly, i.e., at a rate of >5-7 TSS/d/wk for four or more weeks, is often a recipe for disaster in that it appears to frequently lead to illness and/or other symptoms of overreaching/overtraining. Of course, since changes in CTL are “driven” by changes in ATL, this means that any sudden increase in the training load (e.g., training camp, stage race) must be followed by an appropriate period of reduced training/recovery, so as to avoid too great of an overload. To state this idea yet another way: failure to periodically “come up for air” by allowing TSB to rise towards, if not all the way to, neutrality may lead to problems because the training load is being increased too rapidly without allowing for adequate recovery (i.e., ATL >> CTL for too long).
7) The default time constants of the Performance Manager, i.e., 42 d (6 wk) for CTL and 7 d (1 wk) for ATL were chosen as nominal values based on the scientific literature. As with the fitness component of the impulse-response model, the precise time constant used to calculate CTL in the Performance Manager has a limited impact, and although users may still wish to experiment with changing this value, there seems little to be gained from this approach.
On the other hand, the calculations in the Performance Manager are sensitive to the time constant used to calculate ATL, and hence TSB (since TSB = CTL – ATL). Thus, part of the art of using the Performance Manager consists of learning what time constant for ATL provides the greatest correspondence between how an athlete actually feels and/or performs on a particular day vs. how they might be expected to feel or perform based on their CTL/ATL/TSB. Again, experience indicates that younger individuals, those with a relatively low training load, and/or those preparing for events that place a greater premium on sustained power output (e.g., longer time trials, 24 MTB races, long-distance triathlons) may obtain better results using a somewhat shorter time constant than the default value, e.g., 4-5 d instead of 7 d.
Conversely, masters-aged athletes, those with a relatively high training load, and/or those preparing for events that place a greater premium on non-sustainable power output (e.g., shorter time trials, criteriums) may obtain better results using a somewhat longer time constant than the default value, e.g., 10-12 d instead of 7 d. (Of course, since athletes preparing for longer events often – but not always – “carry” higher overall training loads, this tends to constrain the optimal time constant more than would otherwise be the case.)
8) While the Performance Manager is an extremely valuable tool for analyzing training on a macro scale, it is important to also consider things on a micro-scale as well, i.e., the nature and demands of the individual training sessions that produce the daily TSS values. That is, the “composition” of training is just as important as the overall “dose”, and the usefulness and predictive ability of the Performance Manager obviously depend on the individual workouts being appropriately chosen and executed in light of the individual’s competition goals.
To give an example: an elite pursuiter might build their CTL up to the same high level during both a road-focused, level 2/3/4 intense period of training early in the season and during a track-focussed, level 5/6/7 intense period of training immediately before the national championships, but even after a comparable period of tapering (to achieve the same positive TSB, i.e., to gain the same amount of “freshness”) you still would not expect them to perform as well in an actual pursuit earlier vs. later in the season.
Conversely, however, they likely would perform better in a road time trial earlier vs. later in the season because the training they were performing at that time would have been more appropriate, or more specific, for that event. In both cases, however, CTL, ATL, and TSB would still be good indicators of training load and adaptation.
Moreover, it is important to note that this limitation is not unique to the Performance Manager approach but also applies to the impulse-response model as well. Indeed, as Morton et al. (1990) emphasized in discussing the parameters of the criterion performance tests used to establish the time constants and gain factors of the impulse response model: “They must represent best-effort performances on a standard test that is appropriate in length and intensity of effort to the competition event being prepared for.” (emphasis added) In other words, the specificity principle always applies, and this fact should not be overlooked when using (or evaluating) the Performance Manager.
Acknowledgments
I would like to thank the following members of the “eweTSS” list on topica.com for the extremely valuable feedback that they provided during the development and implementation of this analytical tool:
Hunter Allen, Tom Anhalt, Gavin Atkins, Andy Birko, Lindsay Edwards, Mark Ewers, Sam Callan, Chris Cleeland, Tony Geller, Dave Harris, Dave Jordaan, Kirby Krieger, Chris Merriam, Jim Miller, Chris Mayhew, Dave Martin, Scott Martin, Phil McNight, Rick Murphy, Terry Ritter, Ben Sharp, Alex Simmons, Phil Skiba, Ric Stern, Bob Tobin, John Verheul, Frank Overton, Lynda Wallenfells, and Mike Zagorski
(And if any of these folks or those that they train have really been kickin’ butt recently, now you know at least part of the reason why).


